Web scraping
En la economía digital de hoy en día, los datos se han convertido en una fuerza impulsora para el crecimiento y desarrollo de las empresas. Los datos relevantes y precisos pueden ayudar a las empresas a tomar decisiones informadas, y el Web Scraping ha surgido como una estrategia efectiva para adquirir estos datos. En este proyecto, nuestro objetivo es emplear técnicas de web scraping para extraer información útil de una tienda en línea.
Nuestro enfoque será recolectar los nombres de los artículos, los precios e imágenes de los productos de la tienda. Estos datos son fundamentales para el análisis de precios, la investigación de mercado, la estrategia de inventario y más. Al recopilar estos datos, podríamos obtener una visión más clara del posicionamiento de los productos en el mercado y hacer ajustes estratégicos en consecuencia.
Además, los datos recogidos también pueden ser utilizados para una variedad de propósitos analíticos adicionales, tales como el análisis de tendencias de ventas, la identificación de patrones de consumo y la elaboración de estrategias de marketing efectivas.
Este proyecto nos permitirá demostrar las posibilidades de la extracción de datos en la web y su potencial para transformar las operaciones y la toma de decisiones empresariales. Nuestro enfoque sistemático y basado en la tecnología nos permitirá recolectar, procesar y analizar datos a gran escala, superando las limitaciones tradicionales y abriendo nuevas vías de oportunidades comerciales.
BeautifulSoup
BeautifulSoup es una biblioteca de Python que se utiliza para extraer datos de archivos HTML y XML. Fue creada con el objetivo de facilitar el web scraping, una técnica para extraer información de sitios web. BeautifulSoup transforma un documento HTML complejo en un árbol de objetos Python, como listas y diccionarios, lo que facilita la navegación, búsqueda y modificación del parse tree.
BeautifulSoup proporciona unas pocas pero potentes funciones para buscar en el árbol parseado. Puedes buscar elementos por sus etiquetas, atributos, contenido del texto, y más, permitiéndote localizar y extraer cualquier parte del documento.
Aunque BeautifulSoup no descarga páginas web, se puede usar junto con otras librerías de Python como urllib o requests para obtener el código fuente de las páginas web y luego analizarlo.
Nuestro objetivo en esta etapa será extraer información de esta tienda en línea, la cual permite compras bajo la modalidad de Dropshipping. A partir de los datos obtenidos, generaremos un archivo CSV que facilitará la creación de un nuevo catálogo.
La tienda es www.olivostore.pe, de la cual extraemos el nombre, precio, categoria y enlaces de las imagenes. Para cada articulo de la tienda.
Paso 1: Crear la carpeta para las imágenes
Primero, el script crea una carpeta llamada ‘imagenes’ en el directorio actual para almacenar las imágenes de los productos. Si la carpeta ya existe, no se realiza ninguna acción.
Paso 2: Inicializar las listas
El código crea cinco listas vacías: Paginas_list, Price_list, Name_list, Tag_list y Img_list. Estas listas almacenarán los datos que se recolectarán de la tienda online.
Paso 3: Recopilación de las URL de los productos
El script navega por las primeras 10 páginas de la tienda online (cambie este número según sus necesidades). Por cada página, el código busca todos los enlaces (a tags con la clase ‘product-image-link’) y extrae las URL de los productos. Estas URL se agregan a Paginas_list.
Paso 4: Extracción de los datos de los productos
Para cada URL de producto en Paginas_list, el código hace una solicitud HTTP GET para obtener la página del producto. A continuación, extrae los siguientes datos:
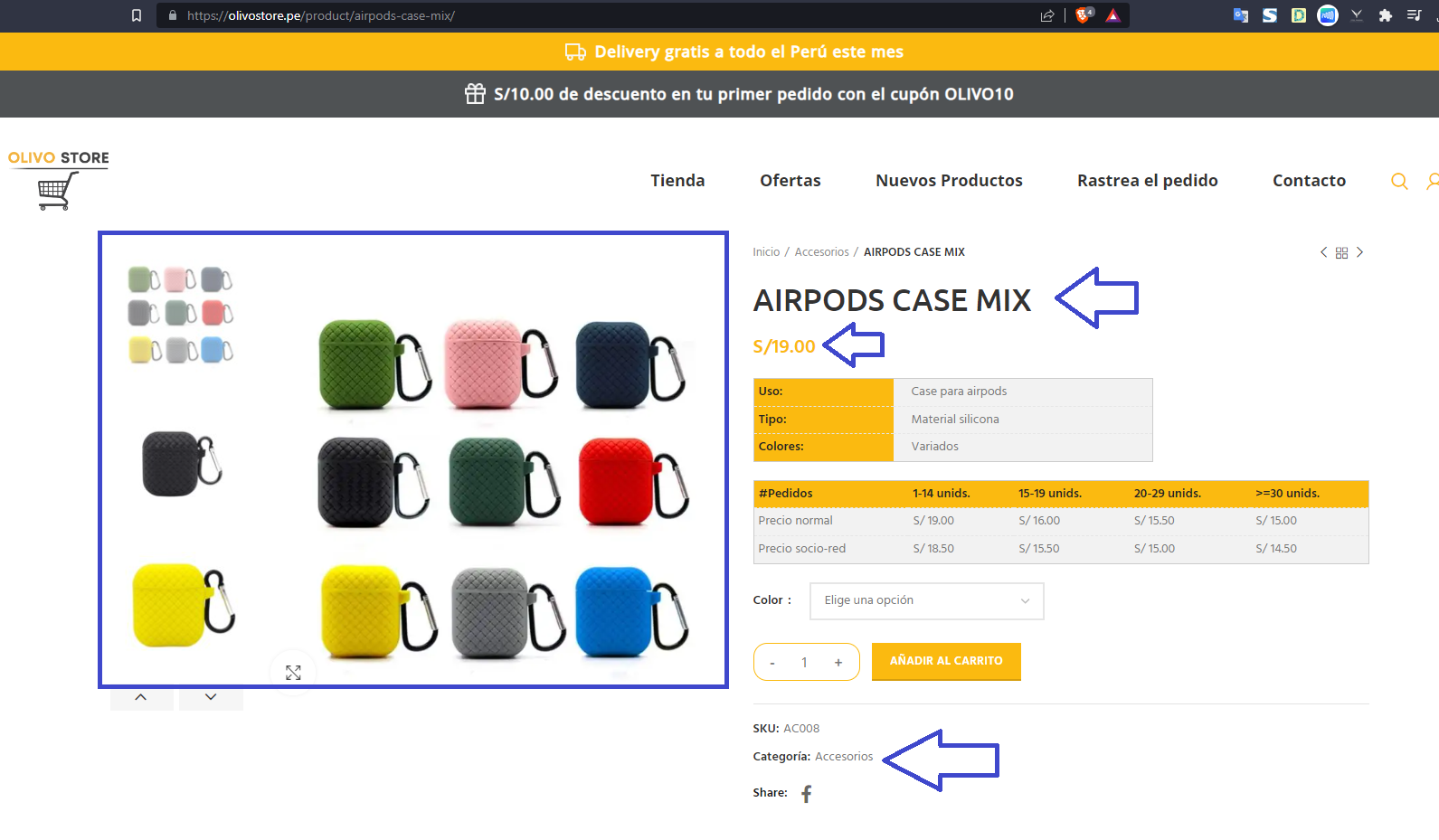
Precio: Busca el elemento p con la clase ‘price’, luego el elemento span dentro de este, y finalmente el elemento bdi. El precio del producto se encuentra en el texto de este último elemento y se agrega a Price_list.
Etiquetas (Tags): Encuentra el elemento span con la clase ‘posted_in’ y extrae todas las etiquetas (a tags) dentro de este. Se crea una lista con el texto de estas etiquetas y se agrega a Tag_list.
Imágenes: Busca todos los div con la clase ‘product-image-wrap’ y extrae las URL de las imágenes. Estas URL se agregan a Img_list. Además, descarga las imágenes de estas URL y las guarda en la carpeta ‘imagenes’.
Nombre: Divide la URL del producto en partes usando el carácter ‘/’. El nombre del producto se toma de la penúltima parte de la URL dividida y se agrega a Name_list.
Paso 5: Crear un DataFrame de Pandas y guardar en un archivo CSV
El script crea una lista Price_buy multiplicando cada precio en Price_list por 1.55. Luego, crea un DataFrame de Pandas con las listas recogidas y Price_buy. Por último, guarda el DataFrame en un archivo CSV llamado ‘olivo_store.csv’.
Este script es una herramienta poderosa para recopilar información de productos de una tienda online. Sin embargo, es importante recordar que el web scraping debe usarse de manera responsable y de acuerdo con las políticas de cada sitio web.

GITHUB
Se puede encontrar el notebook en mi github